
Whether you’re summarising customer reviews, extracting insights from lengthy reports, or analyzing research papers, handling document processing at scale requires thoughtful approaches to manage context limitations. This is where LangChain’s MapReduceDocumentsChain shines as a powerful solution.
Full code snippet at the end 🚀
Table of Contents
Understanding the MapReduce Pattern in LangChain
If you’ve worked with large language models (LLMs), you’re likely familiar with their context window limitations. These models can only process a certain number of tokens at once, creating challenges when dealing with extensive document collections. The MapReduceDocumentsChain in LangChain elegantly addresses this constraint by implementing the classic MapReduce pattern from distributed computing.
But how exactly does this work? Let’s break it down:
- Map Phase: Each document is processed individually by an LLM, creating intermediate outputs
- Reduce Phase: These intermediate outputs are combined (potentially in multiple stages) to produce a final result
This approach allows us to process documents that collectively would exceed the context window of our LLM, making it an essential tool in any AI developer’s toolkit.
Here is a comprehensive guide to cost and token limits considering the Cost of Top 10 LLMs – Compare & Find the Best Budget Option
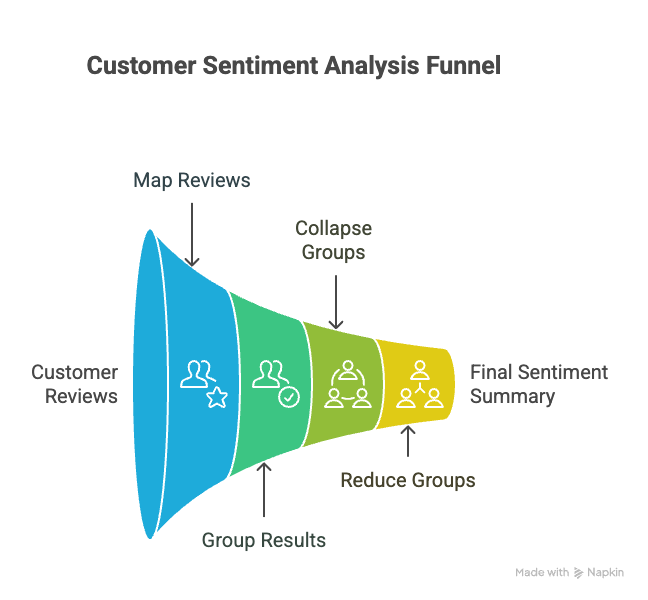
A Real-World Example: Analysing Customer Reviews
To demonstrate the power of LangChain’s MapReduceDocumentsChain, I’ll walk through a practical example analysing smartphone customer reviews using Google’s Gemini model. This example showcases not only basic MapReduce functionality but also the critical token_max parameter and collapse chain mechanisms that prevent context window errors.
Let’s look at the implementation step by step:
Setting Up the Environment
First, we need to import the necessary libraries and set up our LLM:
import os
from langchain.docstore.document import Document
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.map_reduce import MapReduceDocumentsChain, ReduceDocumentsChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.prompts import PromptTemplate
from langchain_google_genai import ChatGoogleGenerativeAI
# Set Gemini API Key
os.environ["GOOGLE_API_KEY"] = "<YOUR_GOOGLE_API_KEY>"
# Load Gemini Model
llm = ChatGoogleGenerativeAI(model="gemini-2.0-flash", temperature=0)You can get your google gemini key for free from https://aistudio.google.com/apikey
Next, we prepare our sample customer reviews:
# Sample Reviews
reviews = [
"The battery life is excellent. I can use the phone for two days without charging.",
"Camera quality is poor in low light. Expected better for this price.",
"Very sleek design and light weight. The screen is super vibrant.",
"Phone charges really fast. But gets hot sometimes during gaming.",
"Audio quality during calls is not good. Gets muffled often.",
"Love the performance. Runs all apps without lag.",
"Display and colors are amazing. Watching videos is a delight.",
"Fingerprint sensor is unreliable. Face unlock is okay.",
"Value for money. Overall very satisfied.",
"The phone lags sometimes while switching apps quickly.",
]
documents = [Document(page_content=review) for review in reviews]Configuring the Map Chain
The Map phase processes each document individually. For our review analysis, we’ll extract positive and negative aspects from each review. Here each review will be considered as a document:
# MAP Prompt
map_prompt = PromptTemplate.from_template("""
You are analyzing a smartphone customer review. Extract the following information and respond strictly in the following format:
- Positive aspects
- Negative aspects
- Common issues or praise
Review:
{page_content}
""")
map_chain = LLMChain(llm=llm, prompt=map_prompt, verbose=True)Setting Up the Reduce and Collapse Chains
Here’s where things get interesting! The Reduce chain combines the mapped outputs, while the Collapse chain serves as a fallback mechanism when token limits are exceeded:
# REDUCE Prompt
reduce_prompt = PromptTemplate.from_template("""
Combine the following summaries into a final concise summary and respond strictly in the following format:
- Overall pros
- Overall cons
- Overall sentiment
Summaries:
{page_content}
""")
reduce_chain = LLMChain(llm=llm, prompt=reduce_prompt, verbose=True)
# Takes a list of documents, combines them into a single string, and passes this to an LLMChain
combine_documents_chain = StuffDocumentsChain(
llm_chain=reduce_chain, document_variable_name="page_content", verbose=True
)
# Collapse Prompt
collapse_prompt = PromptTemplate.from_template("""
Shrink the following summaries into a more concise summary(short in length with minimal grammar) and respond strictly in the following format. Don't miss out any important information:
- Overall pros
- Overall cons
- Overall sentiment
Summaries:
{page_content}
""")
collapse_chain = LLMChain(llm=llm, prompt=collapse_prompt, verbose=True)
# Takes a list of documents, combines them into a single string, while keeping the token_max in check
collapse_documents_chain = StuffDocumentsChain(
llm_chain=collapse_chain, document_variable_name="page_content", verbose=True
)The Power of token_max in Managing Context Windows
Now, let’s focus on one of the most critical parameters in the ReduceDocumentsChain: token_max. This parameter is fundamental to preventing context window errors when working with large document collections.
# Combines and iteratively reduces the mapped documents
reduce_documents_chain = ReduceDocumentsChain(
# This is final chain that is called.
combine_documents_chain=combine_documents_chain,
# If documents exceed context for `StuffDocumentsChain`
collapse_documents_chain=collapse_documents_chain,
# The maximum number of tokens to group documents into.
token_max=200,
verbose=True,
)The token_max parameter specifies the maximum number of tokens to include in each group before the reduce operation. In our example, we’ve set it to 200 tokens, which means:
- Process each customer review individually using the map chain
- Group the mapped results according to the
token_maxparameter. If all the individual review summaries fit into 1 context where token size < token_max then the combine chain will be called for the final result. Note that collapse chain was not triggered here. - If grouping all the mapped summaries into one exceeds the token_max then the group is broken into smaller groups where each group respects the token_max.
- At this point each group will be summarised using the collapse chain. Once done, the flow repeats from Step #2.
- Lastly at some point, multiple summaries would fit into the 1 context where token size < token_max and then the combine chain will be called for a final result. In langchain documentation, they call it “recursive collapsing”, meaning collapse until it first the token_max window.
This approach is crucial when dealing with large document collections or when generating verbose intermediate results. Without token_max, you might encounter:
- Context window errors: When intermediate results collectively exceed the LLM’s token limit
- Processing failures: When the system attempts to process too much text at once
- Performance degradation: Due to inefficient use of the LLM’s context window
Setting an appropriate token_max value requires balancing between processing efficiency (fewer reduce operations) and context window constraints. For most applications, starting with a value at 25-50% of your LLM’s context window is recommended, adjusting based on the verbosity of your intermediate results.
The Collapse Chain: Your Safety Net Against Context Overflows
While token_max helps manage the initial grouping of documents, what happens when even the reduced results collectively exceed your model’s context window? This is where the collapse chain comes into play.
The collapse chain is essentially a fallback mechanism that further condenses information when necessary. In our example, we’ve configured it to create more concise(short/less-tokens) summaries while preserving the essential information:
collapse_prompt = PromptTemplate.from_template("""
Shrink the following summaries into a more concise summary(short in length with minimal grammar) and respond strictly in the following format. Don't miss out any important information:
- Overall pros
- Overall cons
- Overall sentiment
Summaries:
{page_content}
""")Benefits of implementing a collapse chain include:
- Graceful degradation: Instead of failing when document collections are too large, the system continues processing by condensing information
- Adaptability to varying document sizes: Your pipeline can handle both small and large document sets without modification
- Preservation of critical information: With a well-designed collapse prompt, you ensure that key insights are retained even with extreme compression
Think of the collapse chain as your insurance policy against context window errors. Even if your initial estimates for token_max prove insufficient, the collapse chain ensures your processing pipeline remains robust.
Putting It All Together: The Complete MapReduceDocumentsChain
Now that we understand the individual components, let’s see how they come together in the final MapReduceDocumentsChain:
# Create MapReduce Chain
map_reduce_chain = MapReduceDocumentsChain(
# Map chain
llm_chain=map_chain,
# Reduce chain
reduce_documents_chain=reduce_documents_chain,
# The variable name in the llm_chain to put the documents in
document_variable_name="page_content",
# Return the results of the map steps in the output
# return_intermediate_steps=True,
verbose=True,
)
# Run the chain
result = map_reduce_chain.invoke(documents)
# Output Final Summary
print("🔍 FINAL SUMMARY OF CUSTOMER REVIEWS:\n")
print(result["output_text"])When executed, this chain will:
- Process each customer review individually using the map chain
- Group the mapped results according to the
token_maxparameter - Reduce each group using the reduce chain
- If necessary, use the collapse chain to further condense results (if grouping all the mapped summaries exceed the token_max)
- Produce a final summary of customer sentiment
Is collapse_documents_chain optional?
Yes and if you don’t specify it in the ReduceDocumentsChain, the collapse logic will happen with your combine_documents_chain itself. See the description from langchain’s documentation:
param collapse_documents_chain: BaseCombineDocumentsChain | None = None
Chain to use to collapse documents if needed until they can all fit. If None, will use the combine_documents_chain. This is typically a StuffDocumentsChain.Best Practices for Working with MapReduceDocumentsChain
After implementing numerous document processing pipelines with LangChain’s MapReduceDocumentsChain, I’ve developed several best practices that might help you:
1. Carefully Tune Your token_max Parameter
The token_max parameter is crucial for preventing context window errors. Consider these guidelines:
- Start with a conservative value (25-50% of your LLM’s context window)
- Account for the verbosity of your intermediate results
- Test with representative document samples to find the optimal value
- Monitor token usage during processing to identify potential bottlenecks
Remember that setting token_max too low leads to excessive reduce operations, while setting it too high risks context window errors.
2. Design Effective Map and Reduce Prompts
Your prompts significantly impact the quality and efficiency of your MapReduce process:
- Map prompts should extract only the information needed for your final output
- Reduce prompts should effectively consolidate information without excessive verbosity
- Collapse prompts should preserve essential information while aggressively reducing token count
Consider the information flow across your entire pipeline when designing these prompts.
3. Implement Robust Error Handling
Despite our best efforts with token_max and collapse chains, errors can still occur:
- Wrap your MapReduce execution in appropriate try-except blocks
- Implement fallback mechanisms for particularly challenging document sets
- Consider document preprocessing (e.g., chunking very large documents) before entering the MapReduce pipeline
4. Monitor Performance and Adjust as Needed
Document processing at scale requires ongoing monitoring:
- Track token usage across different stages of your pipeline
- Identify processing bottlenecks and adjust parameters accordingly
- Consider parallel processing for the map phase when working with very large document collections
Here is the full code snippet enjoy !







[…] Simple MapReduceDocumentsChain with token_max & collapse_documents_chain […]